Kafka
by HeshAlgo1. Kafka?
대용량, 대규모 메시지 데이터를 빠르게 처리하도록 개발된 메시징 플랫폼
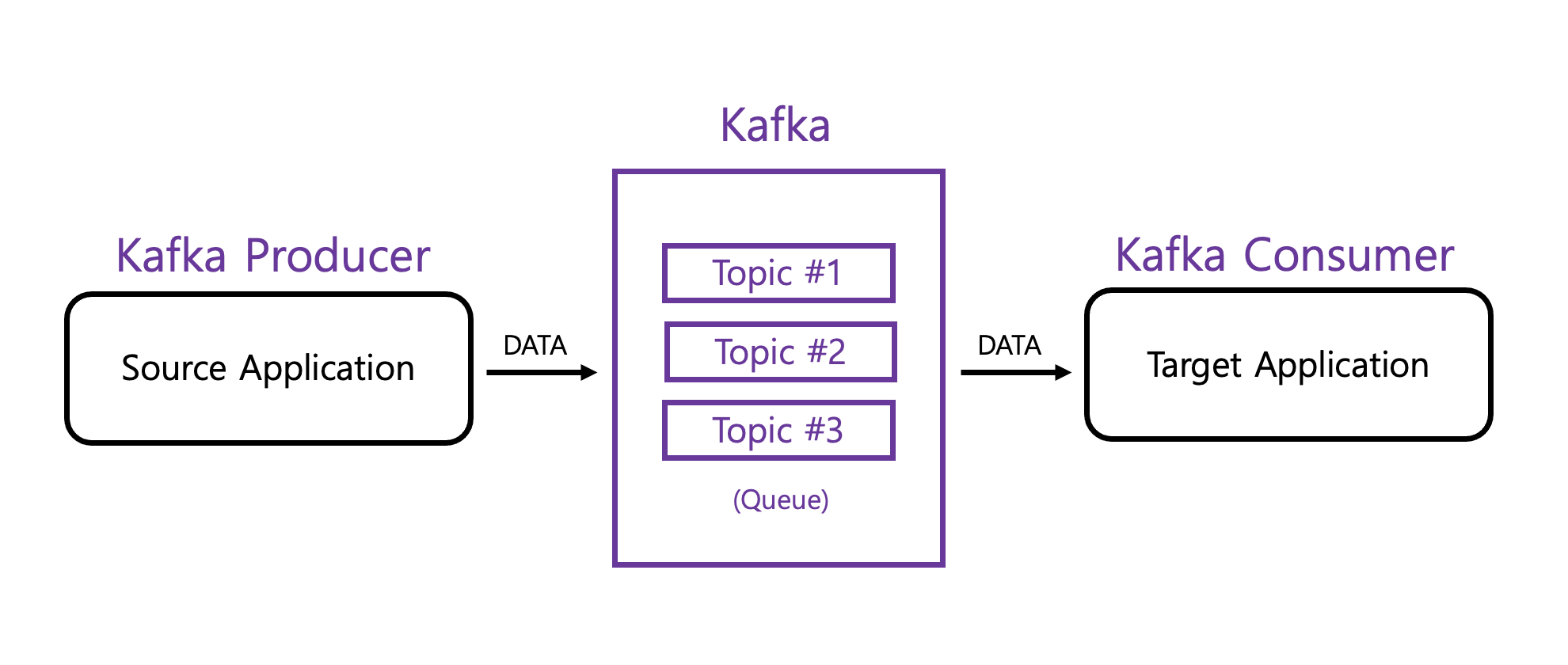
Source Application -> Kafka로 데이터를 전송 (데이터 포맷 제한이 없음)
Kafka -> arget Application로 데이터를 가져옴
목적 : Source Application 과 Target Application의 결합도를 낮추기 위함
확장성과 고가용성을 위해 설계
Producer와 Consumer는 라이브러리로 되어있어서 Application으로 구현 가능
2. Topic
데이터가 들어갈 수 있는 공간
하나의 토픽은 여러개의 파티션으로 구분 가능
1) 파티션이 한 개인 경우

2) 파티션이 여러개인 경우

(1) 키가 Null이고 기본 파티셔너 사용할 경우
-> 라운드 로빈(Round robin)으로 할당
(2) 키가 있고 기본 파티셔너 사용할 경우
-> 키의 해시(hash) 값을 구하고, 특정 파티션에 할당
주의
파티션을 늘릴수는 있지만 줄일 수는 없다.
파티션을 왜늘리는가?
파티션을 늘리면 컨슈머의 개수를 늘려서 데이터 처리를 분산시킬 수 있기 때문에 -> 샤딩이나 병렬처리
파티션의 레코드는 언제 삭제되는가?
-> log.retention.ms : 최대 record 보존 시간
-> log.retention.byte : 최대 record 보존 크기 (Byte)
적절하게 데이터가 삭제될 수 있도록 설정 가능
3. Broker, Replication, ISR(In-Sync-Replication)
1) Broker
카프카 클라이언트와 데이터를 주고받기 위해 사용하는 주체이자, 데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 애플리케이션.
카프카가 설치되어 있는 서버 단위 (보통 3개 이상의 Broker로 구성하여 사용하는 것을 권장)
2) Replication
파티션의 복제
브로커의 갯수에 따라 Replication 갯수가 제한 됩니다.

원본 파티션을 Leader partition
복제 파티션을 Follower partition
원본 파티션 + 복제 파티션 = ISR(In-Sync-Replication)?
Follower partition(복제 파티션)들은 Leader partition(원본 파티션)의 오프셋을 확인하여 자신이 가지고 있는 오프셋과 차이가 나는 경우 Leader partition으로부터 데이터를 가져와서 자신의 파티션에 저장한다.
Producer가 토픽의 파티션에 데이터를 전달할 때 전달 받는 주체가 Leader Partition
Producer에는 ack라는 상세 옵션이 있는데 이를 통해 고가용성을 유지 할 수 있다.
ack는 0, 1, all 중 한개를 골라 설정 가능
(1) ack == 0

Leader Partition에 데이터를 전송하고 Response를 받지 않는다.
-> 그래서 Leader Partition에 데이터가 정상적으로 전달 됐는지 알 수 없고 Replication이 제대로 되었는지 알 수 없음
-> 속도는 빠르지만 데이터 유실 가능성 있음
(2) ack == 1

Leader Partition에 데이터를 전송하고 Response를 받는다.
단, 나머지 Partition에 Replication이 제대로 되었는지 알 수 없다.
마찬가지로 데이터 유실 가능성이 있다.
(3) ack == all

Leader Partition에 데이터를 전송하고 Follower Partition에도 Replication이 잘 되었는지 Response를 받는다.
데이터 유실은 없지만 속도가 느리다는 단점이 있다.
4. Partitioner
데이터를 Topic에 어떤 Partition에 넣을지 메세지 키나 값에 의해서 결정
(Partitioner를 따로 설정 하지 않을 경우 UniformStickyPartitioner로 설정 된다.)
1) 메세지 키가 있는 경우
-> 메세지 키를 가진 레코드는 파티셔너에 의해서 특정한 해쉬값으로 어떤 Partition에 들어갈지 결정
-> 동일한 메세지 키를 가진 레코드는 동일한 파티션에 들어가기 때문에 순서를 지켜서 데이터 처리가 가능
2) 메세지 키가 없는 경우
-> 라운드 로빈 방식으로 결정
-> 파티션에 적절히 분배
Custom Partitioner를 구현할 수 있도록 Partitioner Interface를 제공
5. Consumer Lag
파티션에 데이터가 차곡차곡 하나씩 들어가게 되면 각 데이터에 offset이라는 숫자가 붙는데
Producer가 넣은 데이터의 offset과 Consumer가 가져가는 데이터의 offset 속도가 더 빠르면 이 둘의 차이가 발생하는데 이걸
Consumer Lag(컨슈머 랙)이라고 부른다.
주로 Consumer의 상태에 대해 알아볼때 사용된다.
Consumer가 성능이 안나오거나 비정상 동작을 하게 되면 Lag이 필연적으로 발생
6. Kafka Lag 모니터링을 위한 Burrow
1) 멀티 카프카 클러스터 지원
2) Sliding window를 통한 Consumer의 status 확인
😶 출처
아파치 카프카 프로그래밍 with 자바 (최원영 지음)
'Kafka' 카테고리의 다른 글
| Spring Boot를 활용한 카프카 애플리케이션 개발 (0) | 2021.12.19 |
|---|---|
| Kafka 명령어 (0) | 2021.12.13 |
| 로컬 환경에서 Kafka 구축하기 (0) | 2021.12.12 |
블로그의 정보
꾸준히 공부하는 개발 노트
HeshAlgo