

Elasticsearch 란?
루씬(Lucene) 기반의 Java 오픈소스 분산 검색 엔진입니다. 모든 유형의 데이터에 대해 준실시간에 가까운 검색 및 분석을 제공합니다.
엘라스틱 서치는 Logstash, Kibana와 함께 사용되면서 ELK Stack이라고 널리 알려져 있습니다.
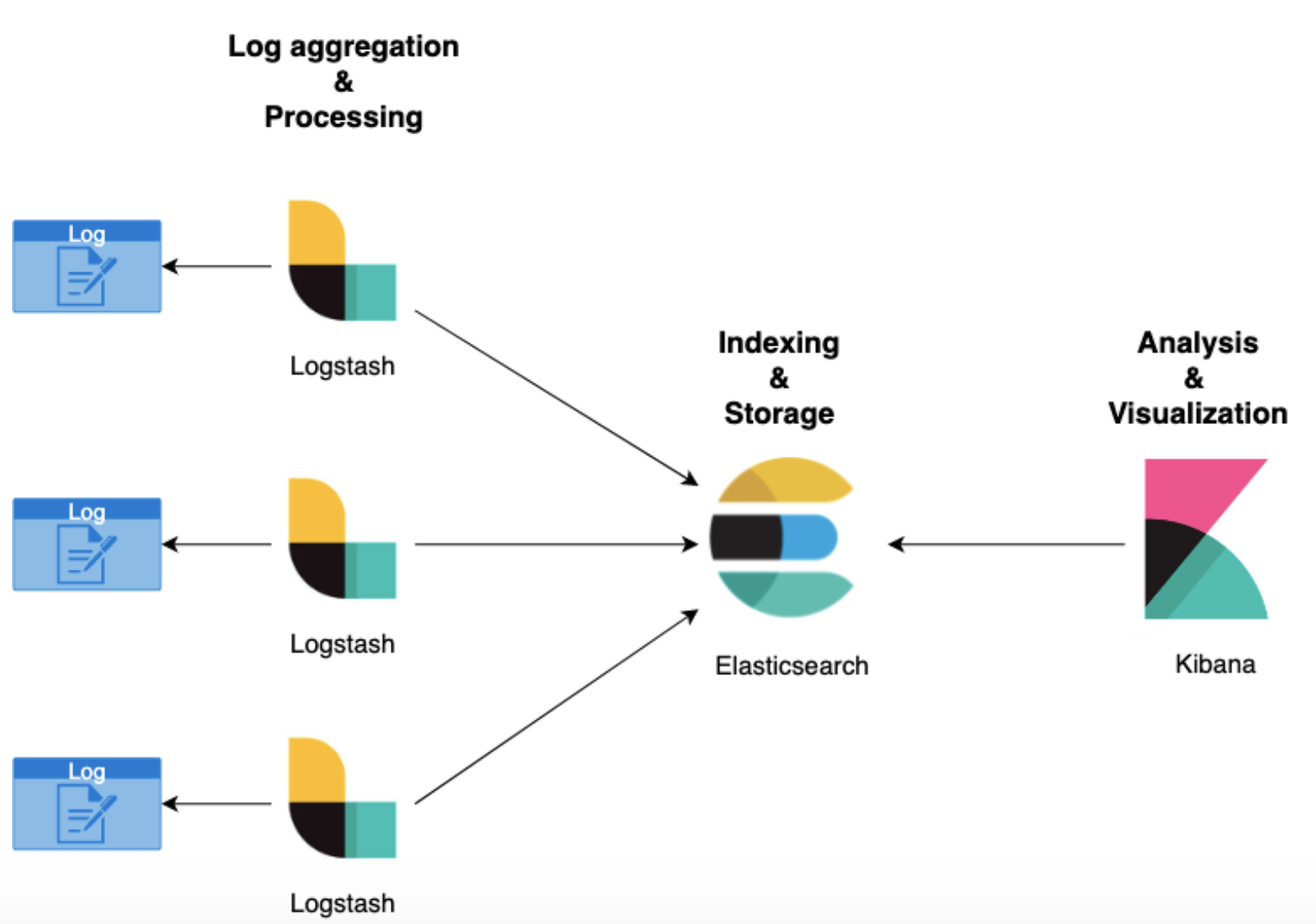
Kibana(키바나) - 엘라스틱 서치에서 제공하는 데이터 시각화 프로그램
Logstash(로그 스태시) - 다양한 소스로부터 데이터를 수집하고 전환하여 원하는 대상에 전송할 수 있도록 하는 경량의 오픈 소스 서버 측 데이터 처리 파이프라인
Elasticsearch 장점
1. 오픈소스 검색엔진
- 엘라스틱서치는 아파치 재단의 루씬(Lucene)을 기반으로 개발된 오픈소스 검색엔진이다. 따라서 버그가 발생할 경우에도 대부분 빠르게 해결된다.
2. 전문 검색
- 내용 전체를 색인해서 특정 단어가 포함된 문서 검색이 가능하다. 엘라스틱 서치는 다양한 기능별, 언어별 플러그인을 조합해 빠르게 검색이 가능하다
3. 통계 분석
- 비정형 로그 데이터를 수집하고 한 곳에 모아 통계 분석을 할 수 있다. 키바나와 연동 시 실시간으로 쌓이는 로그 확인이 가능하다.
4. RESTful API
- HTTP 기반의 RESTful API를 지원하고 요청뿐 아니라 응답에도 JSON 형식을 사용해 개발 언어, 운영체제, 시스템에 관계없이 여러 플랫폼에서도 이용 가능하다.
5. 역색인 구조
- 일반적인 NoSQL은 역색인을 지원하지 않는 반면 엘라스틱서치는 역색인을 지원한다. 특정 단어가 포함된 모든 문서를 찾아야 한다고 가정했을때 일반적으로는 처음부터 끝까지 모든 문서를 읽어야만 원하는 결과를 얻을 수 있지만 역색인 구조는 해당 단어만 찾으면 단어가 포함된 모든 문서의 위치를 알 수 있기 때문에 빠르게 찾을 수 있다.
Elasticsearch 약점
1. 실시간이 아니다.
- 일반적으로 색인된 데이터는 통상적으로 1초 뒤에나 검색이 가능하다. 색인된 데이터는 내부적으로 Commit과 Flush 같은 복잡한 과정을 거치기 때문이다.
2. 트랜잭션과 롤백 기능을 제공하지 않는다.
- 기본적으로 분산 시스템으로 구성되기 때문에 전체적인 클러스터의 성능 향상을 위해 시스템적으로 비용 소모가 큰 롤백과 트랜잭션을 지원하지 않는다.
3. 데이터의 업데이트를 제공하지 않는다.
- 업데이트 명령이 요청될 경우 기존 문서를 삭제하고 변경된 내용으로 새로운 문서를 생성하는 방식을 사용하기 때문이다.
엘라스틱 서치와 관계형 데이터베이스 비교
| Elasticsearch | Relational Database |
| 인덱스(Index) | 데이터베이스(Database) |
| 샤드(Shard) | 파티션(Partition) |
| 타입(Type) | 테이블(Table) |
| 문서(Document) | 행(Row) |
| 필드(Field) | 열(Column) |
| 매핑(Mapping) | 스키마(Schema) |
| Query DSL | SQL |
Elasticsearch를 구성하는 기본 용어
1. 인덱스(Index)
데이터의 저장공간으로 유사한 특성을 가지고 있는 문서(Document)를 모아둔 문서들의 컬렉션
엘라스틱 내부에 생성되는 모든 인덱스는 클러스터 내에서 유일한 인덱스 명을 가져야 하기 때문에 인덱스 명은 매우 중요한 요소기 때문에 인덱스 명은 모두 소문자로 설정해야 하는 것은 필수
인덱스 생성 시 기본적으로 5개의 프라이머리 샤드와 1개의 레플리카 샤드 세트를 생성한다.
2. 샤드(Shard)
매우 많은 양의 문서(Document)가 저장되는 경우를 위해 데이터를 분산 저장하는 방식으로 수평 확장시키는 파티션
즉, 전체 데이터를 분산해서 가지고 있는 일종의 부분집합
설정에 의해 샤드(Shard) 개수를 수정할 수 있고 인덱스(Index)에 쿼리를 요청하면 인덱스가 가지고 있는 모든 샤드로 검색 요청이 전달되고 각 샤드에서 1차적으로 검색이 이뤄진 후 그 결과를 취합해서 최종 결과로 제공
3. 문서(Document)
검색 대상이 되는 실제 물리적인 데이터
JSON 형식으로 표현
물리적인 샤드 형태로 나눠져서 다수의 노드로 분산 저장
4. 매핑(Mapping)
문서의 필드와 필드의 속성을 정의하고 그에 따른 색인 방법을 정의하는 프로세스
5. 클러스터(Cluster)
데이터를 실제로 가지고 있는 노드들의 모임
같은 클러스터 내부의 데이터만 서로 공유가 가능해지기 때문에 연관된 모든 노드는 하나의 클러스터에서 구성원으로 연결되는 것이 매우 중요
6. 노드(Node)
엘라스틱서치 클러스터를 운영하기 위해 다수의 물리 서버에 엘라스틱 서치를 설치하고 실행하게 되는데 이때 실행된 엘라스틱서치 인스턴스를 노드라고 한다.
클러스터를 이루는 구성원의 일부이며 클러스터에 의해 UUID가 할당되고 클러스터 내에서는 할당된 UUID로 서로를 식별
내부에 다수의 인덱스를 가지고 있으며, 각 인덱스는 다수의 문서(Document)를 가지고 있다.
색인 작업을 통해 엘라스틱 서치로 전송한 데이터는 인덱스라는 논리적인 자료구조 속에 문서(Document)라는 형태로 저장된다.
그래서 같은 클러스터 내부에 존재하는 모든 노드는 서로 다른 노드와 수시로 정보를 주고받는다.
안정적인 클러스터 운영을 위해 노드를 각 역할에 맞게 분리해서 운영하는 것을 권장
7. 레플리카 (Replica)
샤드(Shard)의 복제본
인덱스를 생성할 때 기본적으로 1개의 레플리카(Replica) 생성
샤드(Shard) 내부에는 루씬 라이브러리를 포함하고 있는데 이를 이용해 대부분의 검색 기능을 제공
인덱스를 생성할 때 샤드(Shard) 개수와 레플리카(Replica) 개수를 자유롭게 설정 가능
인덱스가 생성된 이후
- 샤드(Shard) 개수 변경 불가
- 레플리카(Replica) 개수 변경 가능
레플리카가 기본적으로 원본 샤드가 존재하지 않는 노드에서 생성되기 때문에 샤드(Shard)나 노드(Node)에 장애가 발생할 경우 즉각적인 복구가 가능한 페일오버(Failover) 메커니즘을 제공하고 있어 이 때문에 안정적인 클러스터 운영을 보장
8. 세그먼트 (Segment)
루씬의 데이터가 색인되면 데이터는 최소한의 단위인 토큰으로 분리되고 특수한 형태의 자료구조로 저장되는데 이렇게 저장된 자료구조를 세그먼트(Segment)라고 한다.
세그먼트(Segment)는 읽기에 최적화된 자료구조로서 역색인이라는 특수한 형태로 변환되어 물리적인 디스크에 저장

참고 문헌 😶
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
Elasticsearch Guide [7.16] | Elastic
www.elastic.co
엘라스틱 서치 실무 가이드 - 저자 권택환, 김동우, 김흥래, 박진현, 최용호
'Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] curl: (52) Empty reply from server (0) | 2022.10.02 |
|---|---|
| 검색과 쿼리 - Query DSL (2) (0) | 2022.05.28 |
| Elasticsearch 데이터 처리 (0) | 2022.02.24 |
| 데이터 모델링 (1) - Settings, Mappings (0) | 2022.01.21 |
| Elasticsearch Node (0) | 2021.12.23 |