

ORM (Object Relational Mapping)
객체지향 패러다임을 관계형 데이터베이스에 보존하는 기술
즉, 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결) 해주는 것
ORM을 통해 객체간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결

JPA (Java Persistence API)
ORM을 사용하기 위한 인터페이스를 모아둔 것
인터페이스이기 때문에 JPA를 사용하기 위해서는 JPA를 구현한 Hibernate, EclipseLink, TopLink 등을 사용해야 한다.
책에서는 Hibernate를 이용해서 구현한다.
프로젝트 생성시 'Spring Data JPA'를 선택하게 되면 Hibernate를 스프링 부트에서 쉽게 사용할 수 있는 추가적인 API를 제공
Hibernate는 '오픈소스'로 ORM을 지원하는 프레임워크이다.


인터페이스를 하나 정의 하는 작업으로 단순 CRUD나 페이지 처리등의 개발 코드를 작성하지 않아도 된다.
JpaRepository를 사용할 때는 엔티티의 정보(Guestbook)와 @Id(Long)의 타입을 지정하게 됩니다.
JPA는 인터페이스 선언만으로도 자동으로 스프링의 빈으로 등록됩니다.
어노테이션 정리
@Entity
- 엔티티 클래스에 반드시 추가해야하는 어노테이션
- JPA로 관리되는 엔티티 객체라는 것을 의미
@Table
- 엔티티 클래스를 어떠한 테이블로 생성할 것인지에 대한 정보를 담기 위한 어노테이션
ex) @Table(name="t_memo") 작성시 't_memo'라는 이름의 테이블 생성
- name속성값이 없을 경우 클래스와 동일한 이름으로 테이블 생성
@Id
- @Entity가 붙은 클래스는 Primary Key에 해당하는 특정 필드를 지정해야한다.
@GeneratedValue
- Primary Key를 자동으로 생성하고자 할 때 사용
- @GeneratedValue(strategy = GenerationType.IDENTITY) 로 사용
@Coulmn
- 필드와 테이블의 컬럼을 매핑시켜주는 어노테이션
- 생략이 가능하며 생략시 필드의 이름이 테이블의 컬럼으로 자동으로 매핑
@Builder
- 객체를 생성할 때 자동으로 builer를 추가해주는 어노테이션
- @AllArgsConstructor와 @NoArgsConstructor를 항상 같이 처리해야 컴파일 에러 발생 방지 가능

@Data
- Getter/Setter, toString(), equals(), hashCode()를 자동으로 생성
Spring Data JPA를 위한 스프링 부트 설정
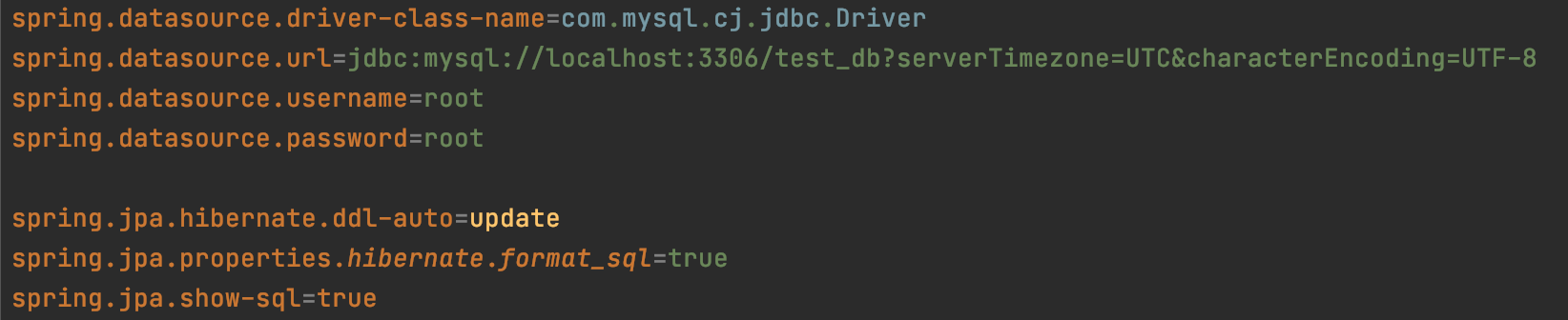
spring.jpa.hibernate.ddl-auto
- 프로젝트 실행 시에 자동으로 DDL(create, alter, drop)을 생성할 것인지를 결정
spring.jpa.properties.hibernate.format_sql
- 실제 JPA의 구현체인 Hibernate가 동작하면서 발생하는 SQL을 포맷팅해서 출력
spring.jpa.show-sql
- JPA 처리 시에 발생하는 SQL을 보여줄 것인지를 결정
페이징 처리
데이터 베이스의 종류에 따라 페이징 처리를 위한 기법을 알아야만 했습니다.
예를 들어 오라클은 '인라인 뷰'를 알아야 했고 My SQL은 'limit'을 알아야만 했습니다.
하지만, JPA는 'Dialect'를 통해 데이터베이스 종류에 따른 기법이 자동적으로 설정 됩니다.
findAll() 메서드를 이용해 페이징과 정렬 처리
파라미터로 전달되는 Pageable이라는 타입의 객체에 의해서 실행되는 쿼리를 결정
| Page<T> findAll(Pageable pageable) |
| Iterable<T> findAll(Sort sort) |
Page<T> 타입으로 지정하는 경우 반드시 파라미터를 Pageable타입을 이용
1. Pageable 인터페이스
인터페이스이기 때문에 실제 객체를 생성할 때는 구현체인 org.springframework.data.domain.PageRequest라는 클래스를 사용
PageRequest 클래스의 생성자는 protected로 선언되어 new 사용 불가.
그래서 객체를 생성하기 위해서는 static한 of()를 이용해서 처리
| of(int page, int size) | 0부터 시작하는 페이지 번호, 개수(size) |
| of(int page, int size, Sort.Direction, String ...props) | 페이지 번호와 개수, 정렬 기준 필드들 |
| of(int page, int size, Sort sort) | 페이지 번호와 개수, 정렬 정보 |
2. 페이징 처리

1) 1페이지의 데이터 10개를 가져오기 위해 파라미터를 (0, 10) 전달
2) findAll()에 의해 페이징 처리에 관련된 쿼리 실행. 쿼리 결과를 알기 위해서 다양한 메서드들을 지원
getTotalPages(), getSize(), hasNext() 등등....
☆ 중요!!
Page타입은 단순히 해당 목록만을 가져오는데 그치지 않고 실제 페이지 처리에 필요한 전체 데이터의 개수를 가져오는 쿼리도 저장합니다.
getTotalPages()메서드를 이용하면 10개의 데이터만 출력하지만 getTotalElements메서드를 이용하면 전체 데이터 개수를 출력 할 수 있습니다.
Thymeleaf
템플릿 엔진으로서 스프링 프레임워크의 MVC패턴 중 V(view)를 담당하는 라이브러리
1. JSP대신 Thymeleaf를 사용하는 이유??
1) ${}를 별도의 처리없이 이용가능
2) Model에 담긴 객체를 화면에서 JavaScript로 처리하기 편리
3) 연산이나 포맷과 관련된 기능을 추가적인 개발 없이 지원
4) 개발 도구를 이용할때 .html 파일로 생성하는데 문제가 없고 별도의 확장자를 이용하지 않음
2. 기본 사용법
1) 반복문 처리
th:each="변수 : ${목록}"
2) 제어문 처리
th:if="${조건}"
3) inline속성
- javascript 처리에 유용
<script th:inline="javascript">
4) 링크 처리
@{}를 이용해서 사용
<a th:href="@{/경로/지정}">
3. Thymeleaf의 레이아웃
1) include 방식
th:replace => 기존의 내용을 완전히 대체 하는 방식
th:insert => 기존 내용의 바깥쪽 태그는 그대로 유지하면서 추가되는 방식
출처
코드로 배우는 스프링 부트 웹 프로젝트 - 구멍가게 코딩단
'개발 일기' 카테고리의 다른 글
| 동기(Synchronous)와 비동기(Asynchronous) / 블로킹(Blocking)과 논블로킹(Non-Blocking) (1) | 2022.04.03 |
|---|---|
| [NHN basecamp] 신입사원 교육 (5주차 ~ 6주차) (0) | 2021.03.10 |
| [NHN basecamp] 신입사원 교육 (3주차 ~ 4주차) (0) | 2021.02.21 |
| [NHN basecamp] 신입사원 교육 (2주차) (1) | 2021.02.01 |
| [NHN basecamp] 신입사원 교육 (1주차) (0) | 2021.01.21 |